如果你使用 Java 开发,你应该听说过 Java 8 引进的 Lambda 表达式,以及用于处理容器类的 Streams API;
如果你用过 JavaScript,你应该也知道高阶函数(如 map/reduce, filter, sort),以及闭包、箭头函数、generator 之类的概念;
如果你上手过 Kotlin,你可能会被里面漫天飞舞的 let, apply, also, with 函数,以及一层层的花括号包裹的 Lambda 表达式感到印象深刻。
这些新鲜玩意初看起来似乎没有那么直观,甚至很别扭:这些代码块什么时候执行、如何被执行,很难一眼看出来!
尝试用一下后,你或许会想“搞这么花里胡哨的,这不就是省得给接口取名字的语法糖嘛”,然后继续写你的匿名内部类;
又或者,你会对这种简洁又新奇的写法感到欲罢不能,恨不得将整个项目都改写为花括号嵌套花括号,最后连自己都看不明白写了个啥。
但这些“新鲜玩意”其实并不新鲜,其历史甚至可以追溯到图灵第一次提出通用图灵机的概念之前!
这篇文章将试图以程序员的视角介绍函数式编程的概念,以及你为什么应该学习使用它的几个理由。
本文将大量使用 Kotlin 作为示例语言,了解 Kotlin 的基本语法,以及高阶函数与 Lambda 表达式有助于理解示例。
考虑到篇幅及受众,本文不会试图介绍一些过于学术或抽象的概念。尽管他们常常与函数式编程一起出现,但你不需要为了理解函数式编程而学习大量的数学。
不理解以下这些概念并不影响阅读本文内容:λ演算(λ-calculus),单子(Monad), 函子(Functor)。
感兴趣的读者可自行搜索了解。
什么是函数式编程
**函数式编程(Functional Programming, FP)**是一种编程范式,它将电脑运算视为函数运算,并且避免使用程序状态以及易变对象。在函数式编程中,函数指的不是程序中的普通函数,而是数学中的函数,即映射关系。以下是一些关键概念:
- 程序的本质:根据输入通过某种运算获得相应的输出。
- 描述输入和输出之间的映射:函数式编程用来描述输入和输出之间的映射关系,即对运算过程的抽象。
- 纯函数:相同的输入始终要得到相同的输出。纯函数不依赖于外部状态,也不会改变外部状态。
在函数式编程中,我们追求整个程序都由函数调用以及函数组合构成。
打个比方,假设你的任务是将一个球通过布满各种可操作的机关和障碍物的场地到达终点。
- 过程式编程就像是你跟着球一起出发,通过场上的装置实时操控球的运动,你无时无刻不在关注:操作了A装置后,球向左偏移了X米,为了到达目的地,下一步需要操作B装置使其向南偏移Y米……最终到达终点;
- 函数式编程则像是你在了解了场上所有装置的作用后,通过事先的计算设置好场上装置的参数,确定了球的运动轨迹。当球出发后,你无需观看和干预,就知道球一定能按照计划到达终点。
在上面的例子中我们可以看到命令式编程和函数式编程在思维方式上的差异。
- 过程式编程关注程序运行中的可变状态(在上面的例子里是球在每一时刻的具体位置),并通过程序指令(操作场上的装置)控制可变状态的变化,达到想要的结果(球的位置到达终点);
- 函数式编程着重于程序运行时输出和输出的映射关系(在上面的例子里,输入是球的初始位置,输出则是球的整体轨迹),通过函数调用与函数组合(对场上装置的参数调整,使得球的轨迹发生变化),使得给定的输入产生预期的输出(球的轨迹通过终点)。
函数式编程中,代码直接操作的往往不是可变的数据,而是函数之间相互调用的关系,代码中更多不是命令式的操作语句,而是声明式的表达式的嵌套。
为了达成函数式编程的魔法,我们需要对程序员的自由做一个重大限制:函数式编程中的函数应该是纯函数,即不应该依赖于可变的状态,也不应该修改外部状态。
你或许会说:“这个条件看上去很苛刻!我们已经太习惯于在函数中读取和操作外部状态,不这样做,我都不知道怎么写代码!”
但请理解,一时的限制是为了更好的抽象,从而写出更加可读、更具表现力的代码。
用上面球与场地的例子来说,给定相同的初始位置(输入),通过相同的函数(相同的场上装置的状态),不管重复多少次,都应该给出相同的结果(球通过终点)。
想象一下如果不是这样会发生什么事情:某个装置使得场地变湿滑,导致结果与场地干燥时不同(结果依赖于可变的外部状态);某个装置只能使用一次,第二次就不能再使用(修改了外部状态:装置被使用过)。
这样的游戏会变得很难玩!
实际上,你已经经历过这样的限制,但并没有影响你写出好的代码,反而使得代码更具可读性与可维护性。
下面这个表格有助于帮你回想这些限制:
| 编程范式 | 附加限制 | 特征技术 | 代表语言 |
|---|---|---|---|
| 结构化编程 (Structured Programming) |
限制控制流的转移 (GOTO语句) |
条件语句,选择语句,循环语句,子程序 | Fortran, Pascal, C |
| 面向对象编程 (Object Oriented Programming) |
限制对数据结构的修改 (非成员函数访问私有变量) |
封装,继承,多态 | Smalltalk, C++, Java, Objective-C |
| 函数式编程 (Functional Programming) |
限制可变状态的访问与修改 (纯函数) |
纯函数,头等函数,闭包,柯里化,懒求值 | LISP, OCaml, Haskell |
好了,空谈无益,show me the code! 接下来我将通过几个示例,介绍过程式编程与函数式编程的差异,及函数式编程带来的好处。
消除可变状态:更易并行化的代码
消除单个状态
假如我们想在 Android 平台实现一个函数,可以从指定的数字开始,每秒倒计时减 1,展示倒计时数字,直到数字减到 0。
为了方便,我们定义下面的工具函数 delayForOneSecond。
1 | private val handler = Handler(Looper.MainLooper()) |
按传统的过程式写法,我们需要一个可变状态量,记录当前倒计时到哪个数字,然后间隔一秒将这个变量减 1,展示倒计时,直到数字变为 0。
1 | private var counter = 0 |
在函数式编程中,我们不希望程序执行中存在可变状态。我们可以使用一个称为“状态传递”的技巧,将可变状态转变为函数的入参,在状态变更时,改变函数入参,并调用函数。
1 | // 将倒计时状态作为函数参数传递 |
初看起来这两段代码做的事情大同小异,甚至传统带状态的写法更容易理解。但考虑以下扩展需求:
- 希望可以展示多于一个正在进行中的倒计时;
- 希望可以在多个线程中同时运行倒计时.
上面代码只涉及一个可变状态,但在实际业务场景中,随着需求迭代需要维护的状态数变多,保证所有状态在所有线程与共享实例都中正确变更的成本也会快速上升。
而使用函数式编程的写法,由于函数执行时参数保持不变,不存在意外篡改或竞态条件的风险,使用函数式编程的代码只需要很少改造甚至无需改造。
在需要并行处理的程序代码中,函数式编程便能发挥其真正的威力。
消除循环变量
在纯函数式编程中,即使像循环变量这样的概念也可以被消除。我们来看看是怎么做的。
下面是使用 for 循环遍历列表的代码,其中使用了循环变量。
1 | fun process(number: Int) = println(number) |
在函数式编程中,可以使用递归代替循环的技巧,从而消除循环:
1 | fun processList(list: List<Int>) { |
另一种更加简洁的写法,是将需要传递的状态由索引 i 改为列表本身:
1 | fun processList(list: List<Int>) { |
在实际开发中,我们往往不追求完全消除可变状态,而是在保持函数式编程优势的情况下,使代码更易读、执行效率更高。因此以上做法仅仅提供一种思路参考,而非推荐实践。
使用头等函数:组合的力量
一种编程语言具有头等函数(First-class Functions),是指在这门语言中,函数可以像普通变量赋值给一个左值、作为函数参数传入,或作为函数返回值返回。
使用头等函数,我们可以对许多代码进一步抽象,将业务逻辑作为函数参数传入,从而编写通用的的工具函数。
例如,想编写一个通用的、遍历列表并做处理的函数,可以这样写:
1 | fun <T> forEachInList(list: List<T>, action: (T) -> Unit) { |
实际上,Kotlin 已经帮我们实现了这样的函数(Collections.forEach):
1 | public inline fun <T> Iterable<T>.forEach(action: (T) -> Unit): Unit { |
再尝试一下,对数组求和呢?
1 | // 数组求和 |
这样写不够“函数式”,因为我们用到了可变状态 sum。通过递归消除循环变量,我们可以改成这样:
1 | fun List<Int>.sumUp(): Int { |
进一步抽象,如果希望遍历数组,并对其中的数据做归并。这里的归并操作可以不仅是累加,还可以是过滤、收集等:
1 | fun <T, R> List<T>.accumulate(empty: R, accumulator: (T, R) -> R): R { |
注意!这里反转了列表遍历的顺序,这样 accumulator 方法执行时,才会从列表的第一个项目开始归并。
因为这里用到的递归的写法,导致计算顺序与循环不同。
在递归压栈时,先传入的参数压在栈底,后传入的参数在栈顶,直到遇到终止条件。
递归计算并退栈时,是从栈顶到栈底一层层计算的,因此后传入的参数会先被计算,计算的顺序与参数传入的顺序相反。
为了使 accumulator 函数的编写者能更符合直觉地编写累加函数(按列表顺序先后取列表元素),压栈的顺序需要取列表顺序的逆序。
假定传入列表为 listOf(1, 2, 3, 4),accumulator = { a, b -> a + b },压栈和计算结果为:
| 栈深度 | accumulator参数列表 |
计算结果 |
|---|---|---|
| 1 | 4, listOf(1, 2, 3).accumulate(...) |
4 + 6 = 10 |
| 2 | 3, listOf(1, 2).accumulate(...) |
3 + 3 = 6 |
| 3 | 2, listOf(1).accumulate(...) |
2 + 1 = 3 |
| 4 | 1, emptyList().accumulate(...) |
1 + 0 = 1 |
注意压栈是从上往下进行,而计算并退栈是从下往上进行。退栈时返回的结果用粗体标明。
回到 accumulate 上来,我们可以用它重写之前的定义的 sumUp 函数:
1 | fun List<Int>.sumUp() = accumulate<Int, Int>(0) { element, sum -> element + sum } |
从 accumulate 基础上,还可以组合出 filter 函数:
1 | fun <T> List<T>.filter(predicate: (T) -> Boolean): List<T> = accumulate(emptyList()) { element, result -> |
具体到业务逻辑:
1 | fun List<Int>.getElementsGreaterThanTen(): List<Int> = filter<Int> { it > 10 } |
我们完全没有用到面向对象编程的继承、抽象接口等特性,仅仅使用高阶函数的组合,就完成了抽象逻辑与具体业务的分离!
闭包:函数运行的上下文
在上面的一些例子中,我们不自觉地在 Lambda 表达式的函数体中,访问了其函数参数之外的变量,而程序代码也像我们想象中一样的运行了。
当你仔细思考这个问题时,你会发现这个实现并不是显而易见的。回顾一下在“消除可变状态”中提到的代码块:
1 | val nextNumber = number - 1 |
在作为 delayForOneSecond 参数的 Lambda 表达式中(其类型为 Runnable),访问了 nextNumber 常量。
nextNumber 常量并不是在这个 Runnable 运行时的环境中定义的,而是在其外层的 countDownFrom 方法中声明并计算出相应值的。
当 Runnable.run() 真正运行时,定义 nextNumber 的环境,也就是上一秒的 countDownFrom 方法,应该早已执行结束并返回,其函数调用栈内的所有临时变量应该都会退栈清除才对!
我们之所以能在函数中自由地访问其定义时上下文的变量,而不会出现任何异常,是语言和编译器帮我们做了许多工作才能达成的。
简单地说,当函数被创建并作为参数被传递时,真正被传递的不仅包含了这个函数指针本身,还有运行这个函数所需的上下文环境。在这个例子中,上下文环境就包含了在函数内部访问的外部变量 nextNumber 的值。
函数的定义与运行函数的上下文的结合,就被称为"闭包(Closure)"。
有了闭包,就能使函数即使脱离了定义函数时的上下文环境,也能独立运行。
而“将函数访问的外部变量作为上下文环境的一部分保存到闭包,使其能在原本的上下文销毁(如函数退栈,对象被回收)后仍然能继续存在”的动作,就称为“变量捕获(variable capture)”
“闭包”这样一个抽象概念,如何实现呢?以 JVM 中匿名内部类或 Lambda 表达式的实现为例,上面的 Runnable 实现就类似于下面(实际情况要比这个复杂,此处仅做简化演示):
1 | // 编译器合成的类定义, |
柯里化:组合函数的万能胶水
面向对象编程中,常常会遇到上层抽象与下层实现之间接口不一致,需要编写适配器(Adapter)将其组合到一起工作。
函数式编程中,也会遇到上层提供的函数与下层的具体业务之间,由于抽象程度不同,要求的函数参数不一致。这时就要用到被称为**柯里化(Currying)**的技巧,将其组合到一起工作。
什么是“柯里化”?柯里化是一种将多参数函数转换为一系列单参数函数的过程,它将外部函数的参数捕获到内部函数的闭包,并返回内部函数,从而减少了函数的参数个数。
我们举一个实际的例子看看。比如,底层框架提供了一个日志方法,允许我们以不同的级别和标签记录日志:
1 | const val LEVEL_VERBOSE = 0 |
对于一个具体业务,可能希望使用固定的标签来记录日志。平凡的做法,会在这个业务内部定义一个函数:
1 | fun logMyBusiness(level: Int, message: String) = log(level, "MyBusiness", message) |
但每个业务都定义一遍这样的函数,也稍显繁琐。另外,当可定义的参数增长时,可以预见重复的样板代码也会随之增长。
又例如,某个三方库(假定叫他 GoodLib)提供了一个接口,用于写入这个三方库内部产生的日志。
1 | // 日志接口定义 |
在不同场景下,可能需要将日志以不同等级写入。
1 | // 适配之前提供的日志方法 |
总结上面问题的共同点:底层框架提供的函数接收三个参数:level, tag, message,而业务层代码使用时,只希望使用一个参数 message 就足够了。
如果我们转换思路,不直接定义业务特定的函数,而是提供一个“函数工厂”,业务可以根据自己需要生成对应的函数,就可以减少重复的样板代码。函数柯里化就是这样的“函数工厂”。
1 | fun loggerOf(level: Int, tag: String): (String) -> Unit = { message -> |
上面的函数捕获了 level, tag 这两个参数,将其作为闭包传递给了底层函数 log,并返回了仅接收一个参数 message 的匿名函数(类型签名为(String) -> Unit),供业务层使用。这个过程就是柯里化。
1 | // 函数式编程中,函数实例可以赋值给常量或者变量。 |
1 | GoodLibSettings.logger = Logger() { channel, message -> |
如果底层框架要求的函数参数比业务使用的要少,也可以通过柯里化的技巧实现转换。下面举个例子。
假定有以下数据类:
1 | class FavoriteItem(val userId: Long, val favorite: String) { |
我们希望为其实现按 userId 过滤列表的方法:
1 | fun List<FavoriteItem>.filterByUserId(userId: Long) = filter { it.userId == userId } |
filterByUserId 函数体接收了 userId 参数,将其通过闭包捕获,返回了一个仅接收 FavoriteItem 类型参数的匿名函数(类型签名为(FavoriteItem) -> Boolean),再立即作为 filter 函数的参数使用。
仅一行简洁优雅的代码,就通过柯里化实现了底层方法的复用与业务自定义逻辑的封装。
消除可变容器:减少错误,提升效率
让我们在前面处理列表的基础上继续扩展功能,看看函数式编程在容器类上应用时的威力。
这里希望筛选出列表中大于 10 的数字。为了着重强调不可变容器的缺陷,我们用 Java 而非 Kotlin 编写。
传统的写法是:
1 | List<Integer> filterNumbersGreaterThanTen(List<Integer> list) { |
使用 Streams API 的写法是:
1 | List<Integer> filterNumbersGreaterThanTen(List<Integer> list) { |
假设上面的需求变更为“取前 5 个大于 10 的元素,并累加”,传统的修改方法是:
1 | int filterFiveNumbersGreaterThanTenAndSum(List<Integer> list) { |
使用 Streams API,函数式编程的修改方法是:
1 | int filterFiveNumbersGreaterThanTenAndSum2(List<Integer> list) { |
两者在代码复杂度、可读性、可维护性上的差异一目了然。
此外,Java 中容器接口默认可变,在工程实践中带来了无数麻烦:
- 业务代码可能意外篡改上层使用的可变容器,导致数据不一致;
- 多线程同时修改可变容器,容易导致
ConcurrentModificationException - 缺乏“不可变容器”的接口与概念,不可变容器只能通过抛出异常来曲折实现,而这一实现方式违背了里氏替换原则。
以下面代码为例:
1 | List<Integer> filtered = filterNumbersGreaterThanTen(list); |
Java 16 中引入的 Stream.toList() 方法返回的是不可变列表(Collectors.toList() 返回的是可变列表),也是为了鼓励使用不可变容器。
Kotlin 的容器接口(Collection/Map/Set/List)默认不可变,而可变容器是扩展自不可变容器的独立接口 MutableCollection/MutableMap/MutableSet/MutableList。
这样,即使函数内部处理时使用了可变容器,返回的容器对象也默认是不可变的(不存在 add/remove 这样修改容器的接口,从而在编译期检查到错误)。
懒求值:消除多余操作
在使用 Java Streams API 时,你或许会有这样的担心:如果我使用 limit() 函数声明只取列表中的头几个元素,实际执行时会不会先取全部元素,再移除多余的元素?在数据量大时会不会影响性能?
不必担心,因为 Java Streams API 的函数调用都是懒求值的:当你链式调用 filter / map / limit 这类返回 Stream 对象的函数时,Stream 内部并不会立即执行声明的操作,而是将其暂存下来。
只有当 Stream 进入末端操作(转换为列表、容器、进行归并)时,才会实际发生计算,而多余的计算不会执行。
懒求值(Lazy evaluation)的概念对许多人应该并不陌生。最常见的,使用逻辑或串联的表达式中,如果前面的表达式求值结果为 true,则后面的表达式不会被求值,因为整个表达式的值已经确定为 true 了,只有真正需要子表达式的值来判断整体的值时,子表达式才会求值。这就是一种懒求值。
与之相对的是积极求值(Eager evaluation),也就是表达式定义出现时就对其进行求值。
函数式编程中头等函数的设计,方便了懒求值的应用。将函数作为参数传递时,执行函数所需的上下文也会一并捕获,作为闭包传递。因此,我们可以延迟函数的执行,直到真正需要获取函数执行结果时,才对函数进行求值。
Kotlin 中,针对容器类操作,既有积极求值的 API (kotlin.collections.filter/map/take),也有类似 Java Streams API,使用懒求值的 Sequences API。下面是 Kotlin 官方文档中给出的两个例子:
1 | val words = "The quick brown fox jumps over the lazy dog".split(" ") |
1 | val words = "The quick brown fox jumps over the lazy dog".split(" ") |
可以注意到以下两点:
kotlin.collectionsAPI 对列表元素的操作是立即执行的(内部输出在打印标题语句之前);而 Sequences API 对Sequence中元素的操作延迟到了toList()调用之后才实际发生(内部输出在打印标题语句之后)kotlin.collectionsAPI 先对列表中的所有元素进行了filter操作,再对过滤后的列表所有元素进行了map操作,最后将映射后的列表缩减到要求的大小;而 Sequence API 在列表中的元素达到 4 个之后,就停止了filter和map操作,没有多余的计算发生。
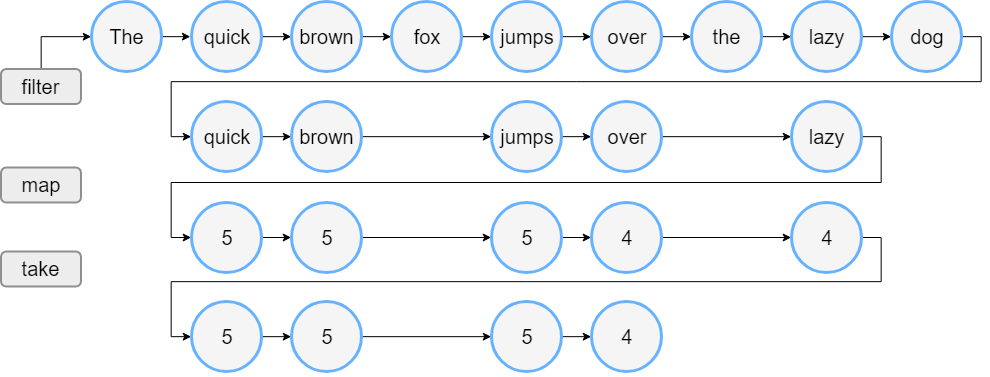
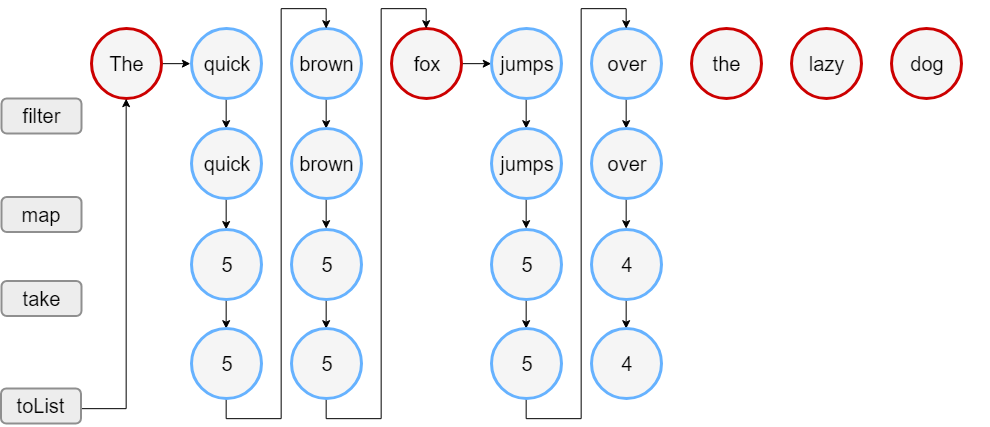
这就是懒求值的好处:直到收集完所有信息并不得不完成计算时,计算才会发生,此时,我们可以利用之前收集到的信息消除冗余操作,避免无谓的计算资源的消耗。
不过,无论是 Java Streams API,还是 Kotlin Sequences API,实现懒求值的代价是一些额外的性能开销,在小的集合上,这些 API 的效率可能不如传统的积极求值方式,使用者应该根据实际情况选择合适的 API。
硬币的反面:性能与可读性
如果你是初次接触函数式编程的新手,看了这些眼花缭乱的例子,你或许会对这种新颖的组织程序逻辑的方式与“状态不可变”的思想感到新奇。
但在拥抱函数式编程之前,你或许还有一些不确定:
- 函数式编程会影响性能吗? 将过程式的写法改写成函数式写法后,平白无故多了许多次函数调用,带来压栈出栈的开销;每次函数作为参数传递时,又会创建闭包,这样做对性能是否有影响?
- 函数式编程是否会导致项目的可读性与可维护性变差? 相对于传统编程范式,函数式编程可以将函数作为函数参数或返回值,不熟悉函数式编程的人员阅读这种代码时容易感到困惑。另外,函数式编程的特点,使得其代码执行流不容易一下子看出来(控制经常会从一个函数转移到另一个函数,而这些函数又往往是作为函数参数传入的,增加了复杂度),也增大了调试程序的难度。
这些问题的答案也不是简单的“是”或“否”能概括的,经常需要具体情况具体分析。
函数式编程的性能问题
简短回答:
某些情况下,函数式编程可能会负面影响性能,但大多数情况下不像你想象的那么大。大多数情况下,你更应该关心更高级的抽象是否带来了开发速度与项目管理上的优势。此外,函数式编程使得编写大规模并行代码变得更容易,在某些场景下(服务器编程、并行计算)会提供性能优势。
较长的回答:
函数式编程的一些特征,会使其在运行时使用更多的内存空间与计算资源,具体来说体现于以下方面:
- 上下文切换频繁:函数式编程往往会对方法进行过度包装,产生许多中间调用,导致上下文切换的性能开销。
- 资源占用:为了实现对象状态的不可变,函数式编程倾向于创建新的对象,这会对垃圾回收产生压力。
- 递归陷阱:函数式编程中,为了实现迭代,通常会采用递归操作,但递归可能导致性能问题。
针对这些问题,现代编程语言(特别是鼓励函数式编程范式的语言)在编译时与运行时,会进行大量的性能优化。
编译时常见的优化策略有:
- 内联(Inlining):编译器可以将函数调用处的代码直接替换为函数体,减少函数调用开销。
- 尾递归优化(Tail recursion optimization):对尾递归函数进行优化,通过消除压栈退栈操作,避免递归栈溢出。
- 常量折叠(Constant Folding):在编译时计算常量表达式的值,减少运行时计算开销。
- 静态类型检查:在编译时检查类型错误,避免运行时类型转换开销。
运行时常见的优化策略有:
- 缓存:缓存中间结果,避免重复计算。
- 懒加载(Lazy Evaluation):延迟计算,只在需要时才进行计算,减少不必要的开销。
- 不可变数据结构:使用针对不可变对象进行优化的数据结构(如写时复制列表),避免频繁的对象创建和拷贝,并减少内存占用。
- 并发和并行:对于明确没有副作用的代码块,可以利用多线程并发执行任务,提高性能。
函数式编程的可读性与可维护性问题
简短回答:
用好函数式编程,确实需要开发者对其有一定程度了解,对开发者的逻辑思维能力提出了更高要求,但这对任何编程范式或技术来说都是如此。工程使用中应当扬长避短,将函数式编程范式用在其适合的领域。
较长的回答:
软件工程没有银弹,正如其他所有编程范式一样,大量使用函数式编程的实际工程项目中,不可避免会出现一些可读性与可维护性问题,典型的如下:
- 嵌套函数层级过深:函数式编程使用函数组合与嵌套实现封装与模块化,但就像面向对象编程过于复杂的继承关系会使代码难以阅读和维护,函数式编程中嵌套函数层级过深,也容易导致可读性和可维护性降低;
- 隐式依赖:函数式编程中,参数的输入与输出除了通过参数列表与返回值传递,还可能通过闭包或其他上下文传递。这可能造成不易发现的隐式依赖,增加代码重构与问题排查的难度。
- 新人训练成本较高:对于习惯了过程式与面向对象编程,而不熟悉函数式编程的新人,上手项目可能需要一定时间,因为常见的一些概念(可变状态与数据结构,类封装)在函数式编程中并没有对应物,而头等函数、状态传递、柯里化等函数式编程的概念需要多加联系才能理解并掌握。
- 调试难度较大:函数式编程中不鼓励使用可变状态,因此调试时往往不能直接修改状态来查看效果;在不可避免地需要处理副作用的逻辑时(如IO操作、网络请求),往往难以追踪其状态变化。
针对函数式编程的特点,最好是将其应用于其适合的领域,而不是试图将其用于解决所有业务问题。
- 适合的领域:
- 数学和科学问题:函数式编程的数学基础使其在解决数学和科学领域的问题时非常有效。纯函数的不变性有助于确保正确性。
- 数据处理和转换:函数式编程适用于数据流处理、转换和过滤。例如,处理大量数据、清洗数据、映射、过滤等操作。
- 并发和分布式系统:函数式编程的不可变性和纯函数特性使其在并发和分布式环境中更易于调试和维护。
- 不适合的领域:
- 复杂业务逻辑:对于复杂的业务逻辑,函数式编程可能过于抽象,难以理解和维护。在这些情况下,面向对象编程可能更合适。
- 性能要求极高的场景:函数式编程的函数调用开销较大,不适合对性能要求极高的场景。在这些情况下,结构化编程或优化的面向对象编程可能更合适。
- 与外部状态强相关的问题:函数式编程不擅长处理与外部状态强相关的问题,例如GUI应用程序、游戏引擎等。